C++ atomic객체
1. 개요
오늘은 C++ 의 atomic객체에 대해 공부하도록 하겠습니다.
2. Race Condition
C++에서 모든 쓰레드들이 전부 랜덤하게 작용합니다.
아래의 코드를 보시겠습니다.
#include<iostream>
#include<atomic>
#include<thread>
#include<vector>
using namespace std;
void worker(int& cnt)
{
for (int i = 0; i < 10000; i++)
{
cnt++;
}
}
int main()
{
int cnt = 0;
vector<thread> workers;
for (int i = 0; i < 4; i++)
{
workers.push_back(thread(worker, ref(cnt)));
}
for (int i = 0; i < 4; i++)
{
workers[i].join();
}
cout << cnt << '\n';
return 0;
}저희는 4만을 기대하고있습니다.
하지만


엥 이게 왠일이죠? 숫자가 뒤죽박죽입니다.
그 이유는 앞서 배웠던 Race Condition에 대해 있습니다.
쓰레드의 자원을 동시에 접근하여 경쟁상태가 되고 ++를 해줘야할것을 못해주기 때문입니다.
(쓰레드 1이 캐시에서 CPU가 레지스터로 가져왔는데 쓰레드 2가 값 1인 것을 똑같이 가져와 결국 3이되야할게 2로 되는현상)
https://chogyujin-study.tistory.com/104
Race Condition 경쟁상태
1. 개요 오늘은 OS에 경쟁상태 Race Condition에 대해서 공부하도록 하겠습니다. 2. Race Condition(경쟁상태)? 경쟁상태란 두 개 이상의 cocurrent한 프로세스(혹은 스레드)들이 하나의 자원(리소스)에 접근
chogyujin-study.tistory.com
3. Atomic
Atomic 객체는 말 그대로 원자 라는 뜻으로 경쟁 상태를 해결하는데 도움이 됩니다.
모든 쓰레드들이 수정 순서에 동의해야만 하는 경우는 바로 모든 연산들이 원자적 일 떄, 원자적인 연산이 아닌 경우에는 모든 쓰레드에서 같은 수정 순서를 관찰할 수 있음이 보장되지 않기에 여러분이 직접 적절한 동기화 방법을 통해서 처리해야 합니다. 만일 이를 지키지 않는다면, 프로그램이 정의되지 않은 행동(undefined behavior)을 할 수 있습니다.
그렇다면 원자적 이라는 것이 무엇일까요?
이미 이름에서 짐작하셨겠지만, 원자적 연산이란, CPU 가 명령어 1 개로 처리하는 명령으로, 중간에 다른 쓰레드가 끼어들 여지가 전혀 없는 연산을 말합니다. 즉, 이 연산을 반 정도 했다 는 있을 수 없고 이 연산을 했다 혹은 안 했다 만 존재할 수 있습니다. 마치 원자처럼 쪼갤 수 없다 해서 원자적(atomic) 이라고 합니다.
C++에서는 몇몇 타입들에 원자적인 연산을 쉽게 할 수 있도록 여러가지 도구들을 지원하고 있습니다.
또한 이러한 원자적 연산들은 올바른 연산을 위해 굳이 뮤텍스가 필요하지 않습니다. 즉 속도가 더 빠릅니다.
#include<iostream>
#include<atomic>
#include<thread>
#include<vector>
using namespace std;
void worker(atomic<int>& cnt)
{
for (int i = 0; i < 10000; i++)
{
cnt++;
}
}
int main()
{
atomic<int> cnt(0);
vector<thread> workers;
for (int i = 0; i < 4; i++)
{
workers.push_back(thread(worker, ref(cnt)));
}
for (int i = 0; i < 4; i++)
{
workers[i].join();
}
cout << cnt << '\n';
return 0;
}
기대하는 값이 잘 나옵니다.
뮤텍스의 보호도 없이 정확히 4만이 나왔습니다. cnt++을 하기 위해서는 CPU가 메모리에서 cnt 의 값을 읽고 더하고 쓰는 총 3개의 단계를 거쳐야만 했습니다. 그런데 여기서는 lock 없어도, 제대로 계산이 되었습니다.
그럼 컴파일러는 이를 어떻게 원자적 연산으로 만들었는지 어셈블리 코드를 생성해봅시다.
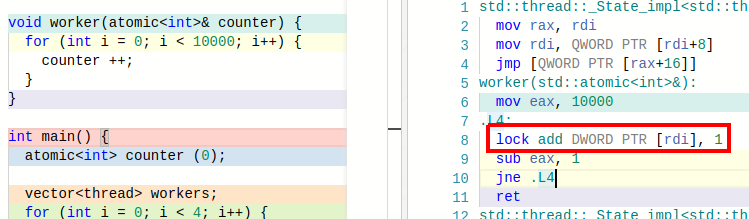
lock add DWORD PTR [rdi], 1이 부분이 cnt++ 부분이며 lock add 는 rdi 에 위치한 메모리를 읽고 1 더하고 다시 rdi 에 위치한 메모리에 쓰기를 모두 해버립니다.
참고로 이러한 명령어를 컴파일러가 사용할 수 있었던 이유는 우리가 어느 CPU 에서 실행할 지 (x86) 컴파일러가 알고 있기 떄문에 이런 CPU 특이적인 명령어를 제공할 수 있던 것입니다.
물론, CPU에 따라 위와 같은 명령이 없는 경우도 있습니다.
이 경우 CPU는 위와 같은 원자적인 코드를 생성할 수 없습니다.
이는 해당 Atomic 객체의 연산들이 과연 정말로 원자적으로 구현될 수 있는지 확인하는 is_lock_free() 함수를 호출해보면 됩니다.
#include<iostream>
#include<atomic>
#include<thread>
#include<vector>
using namespace std;
void worker(atomic<int>& cnt)
{
for (int i = 0; i < 10000; i++)
{
cnt++;
}
}
int main()
{
atomic<int> cnt(0);
vector<thread> workers;
for (int i = 0; i < 4; i++)
{
workers.push_back(thread(worker, ref(cnt)));
}
for (int i = 0; i < 4; i++)
{
workers[i].join();
}
cout << cnt << '\n';
cout << cnt.is_lock_free() << '\n';
return 0;
}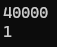
사진과 같이 나오며 여기서 lock free의 lock 과 실제 어셈블리 명령에서의 lock과는 다른 lock을 의미합니다.
위 어셈블리 명령어에서 lock은 해당 명령을 원자적으로 수행하라는 의미로 사용되며, lock free에서의 lock이 없다 라는 의미는 뮤텍스와 같은 객체들이 lock, unlock 없이도 해당 연산을 올바르게 수행할 수 있다는 뜻 입니다.
4. Ref
씹어먹는 C++ - <15 - 3. C++ memory order 와 atomic 객체>
여러분의 코드는 여러분이 생각하는 순서로 작동하지 않습니다. (단일 쓰레드 관점에서) 결과값이 동일하다면 컴파일러와 CPU 는 명령어의 순서를 재배치 할 수 있습니다. 문제는 이렇게 마음대
modoocode.com